Did you know Google have their own “10 Commandments” (ok, more 10 Philosophy things – but my way sounds better). It’s always a bit interesting to see things from inside the Googleplex and it has lots of “odd jokes” – such as “It’s best to do one thing really, really well… Google does search”: Google now do a lot more than search! And not to forget “Google believes in instant gratification” 😉
Category: Net: Search Engines
I’ve found something that the all-knowing and all-seeing Google cannot find! Streets in New Zealand. This is despite these streets being in its database!
So how can we pull up a nice Satellite view of a New Zealand street? Here’s how I did it.
First of all, know the name of the street you are looking for. For this example, I will use “Reeves Road” in Christchurch (South Island).
Now go to http://www.wises.co.nz/ and search for that road to make a map.
Now zoom out on the Wises map to get a good overview of the area.
Now go to Google maps at http://maps.google.co.uk and type in “Christchurch, New Zealand” to get as close as Google will allow you to search.
Compare the two maps until you can match up the major road names/locality names.
Zoom in on Google maps and low and behold – there’s your street! With it’s street name!
If you want to then see it in Google Earth (which doesn’t have street names and has the same resolution photos), then click “Link to this page” and in the URL bar at the top of Firefox/Internet Explorer, copy the &ll=-49……. section until the next & sign and copy that bit into Google Earth.
There you go – not that difficult, but fiddly.
A fellow blogger has suggested that a tag be introduced which would stop search engines such as Google from indexing certain sections of web pages. This would be extremely handy for all the blog comment spam which is currently going around (I’m personally using a combination of IP blocking [like Neil] and modification of /lib/MT/App/Comments.pm to block certain words in submitted URLs), but instead of
>!-- SearchEngine: Begin Anonymous Comment --> / <!-- SearchEngine: End Anonymous Comment -->
I would recommend something a bit more generalised such as:
<!-- robots:noindex --> / <!-- /robots:noindex -->
To try and fit in with the already existing robots.txt and robots meta tag (it also could be extended to things like <!– robots:nofollow –> for sections of content).
This tag would be used to mark sections of web page content as being “not to index/search”: so if a spammer does managed to add their URL to a website, but the URL appears in between the <!– robots:noindex –> tag then the search engines will ignore the listing making the spam useless in regards to search engine placement/promotion.
However, there’s a number of drawbacks that I can see for this introduction to the search engine world:
LOL (laugh out loud!). Being a typical geek, I tried several calculations in the Google Calculator to get a screenshot showing 42: but I should have remembered my Douglas Adams and just searched for “answer to life, the universe and everything”.
No kidding – Google returns “answer to life, the universe and everything = 42” – try it yourself!.
I now also know roughly how much I weigh in kilograms ( 13 stones to kilograms : yes, Google does conversions as well), I’m sure that “four and twenty” does actually mean twenty four blackbirds, and I know how many Newtons I need to travel back in time to a fortnight plus 17 days ago with my copy of “555.6 kilometers under the sea.
Kewl! (well, it keeps me entertained).
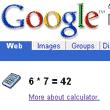 Alright, own up – who erased my memory so that I knew nothing about the Google calculator function until jake at Utterly Boring blogged about it? To think, I won’t have to drop to the command line at work and do
Alright, own up – who erased my memory so that I knew nothing about the Google calculator function until jake at Utterly Boring blogged about it? To think, I won’t have to drop to the command line at work and do perl -e "print 6*7 when I want to do quick sums anymore (yes, yes, Windows has a calc.exe function – but I just don’t like it for a reason I’m unable to explain to myself).
And there I was thinking that Google News Alerts was the latest thing to be offered by “the big G” (whose anti site Google Watch now has a watch site of it’s own Google Watch Watch [as spotted by Neil]).